DeepScribe Beats GPT4 by 59% on AI Scribing, But It's Not Enough
OpenAI's GPT4 is changing the AI landscape — and the world at large. The principal question we're asking is: How does GPT4 fare in healthcare?


Editor's note (updated 2025): This 2023 article reflects an earlier stage of DeepScribe’s technology and evaluation methods. Today, notes delivered to clinicians are generated entirely by our AI system, with humans involved only in offline evaluation and model improvement. For our latest quality framework, see our DeepScore documentation.
It’s an understatement to say that OpenAI’s ChatGPT is the biggest breakthrough in NLP, perhaps AI in general. In just a few short months, it has brought AI to the forefront of our national discourse and reshaped how global leaders are thinking about the future of work, economics, education, and much more. However, the near viral adoption of GPT4 (OpenAI’s latest large language model) raises a host of questions about the accuracy of AI solutions and how to deploy them safely in business. At DeepScribe, one of the principal questions we’re asking is: How does GPT4 fare in healthcare?
In healthcare, where trust and safety are paramount, this is the critical question that needs an answer, especially as the AI scribing industry as a whole continues to leverage GPT4 as a means of accomplishing “full automation.” Our hypothesis was that GPT4, like other non-specialized models, would be prone to hallucinations, inconsistent responses, and other domain-specific hurdles. We wanted to put that hypothesis to the test. More specifically, we set out to answer the following questions:
Can a doctor plug a medical transcript into GPT4 and receive accurate and meaningful medical note outputs? Is it a viable option for clinicians (HIPAA and PHI issues aside)? Can it be trusted? Is it accurate?
Before we get into the methodology and results of this study, let’s first consider why automating medical documentation is such a hard problem to solve.
Hard Input
Hard input refers to input data that is difficult for an AI system to process or interpret. In AI documentation, there are three elements of hard input that complicate the process: Crosstalk, Long Transcripts, and Noisy Environments.
Crosstalk
Crosstalk refers to the tendency for two or more speakers to talk over each other and interrupt each other during natural conversation. This abrupt, stop and start pattern makes it difficult to create a linear narrative of events and appropriately identify and classify medical concepts.
Long Transcripts
Long, meandering patient visits can create lengthy transcripts that are difficult for an AI system to comb for medical concepts. The longer the visit, the longer the transcript, and the more data that needs to be processed and filtered.
Noisy Environments and Annunciation
High fidelity audio is one of the keys to success in AI scribing. If that audio is disrupted by outside noise (doors closing, people talking outside, etc.), transcript quality and ultimately note quality will suffer. Combined with difficulty in deciphering unclear speech or poor annunciation, procuring high quality transcripts is a difficult task.
Error Tolerance
Errors in medical documentation can have profound negative effects on patients, clinicians, and entire practices. Incorrectly documenting a symptom or medication can result in malpractice lawsuits or be the difference between life and death, meaning it is critical to deploy these models responsibly.
Disjointed Concepts
With naturally disjointed conversations, AI systems are left with disjointed, non-continuous data. These systems must then take this disjointed data, with disjointed concepts and use it to paint a picture that is highly accurate. AI scribing can be compared to completing a puzzle with your eyes closed.
Trillions of Combinations of Progressions
In addition to making sense of disjointed concepts, the AI must arrive at medically accurate conclusions despite there being trillions of potential outcomes. The more complicated a visit is, the more permutations the AI must consider.
All of these difficulties exist only in regards to the note generation process, and don’t include the difficulties in producing notes that align with clinician preferences, templates, electronic health record systems, workflows, etc.
Methodology
Note: DeepScribe’s medical notes are fully AI-generated. Humans are involved only in offline evaluation, research, and model improvement, not in writing or editing the clinical notes clinicians receive.
Here’s what we did. First, we gathered a statistically significant sample of "test" encounters and created a grading rubric that we could apply to outputs from both DeepScribe and GPT4. Using a group of experienced medical scribes, each test encounter was documented to accuracy standards, audited by other scribes, and reviewed by a panel of analysts. In essence, we asked domain experts to create standardized notes in an offline research setting and then used those notes as the denominator with which we graded the accuracy of notes produced by DeepScribe and GPT4. These reference notes were never delivered to clinicians and were only used as ground truth for this study. Note outputs from each platform were anonymized and sent through the same grading process (scribes, audit, panel) where note defects were categorized, labeled, and then compared against the standardized note.
While both models showed tendencies to produce minor errors related to spelling, grammar, and duplications, this test focused primarily on the prevalence of “critical defects” such as AI hallucinations, missing information, incorrect information, and contradictions. By filtering out minor errors that do not compromise the clinical integrity of a medical note and can be improved through subsystem models and boosting, we were able to get a more distilled view of the clinical viability of both AI solutions.
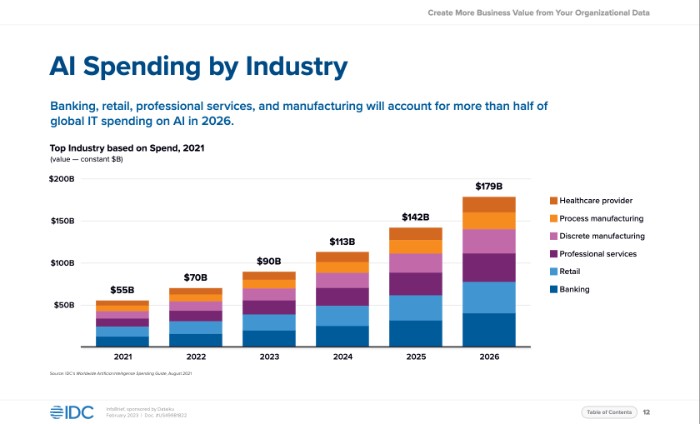
Results
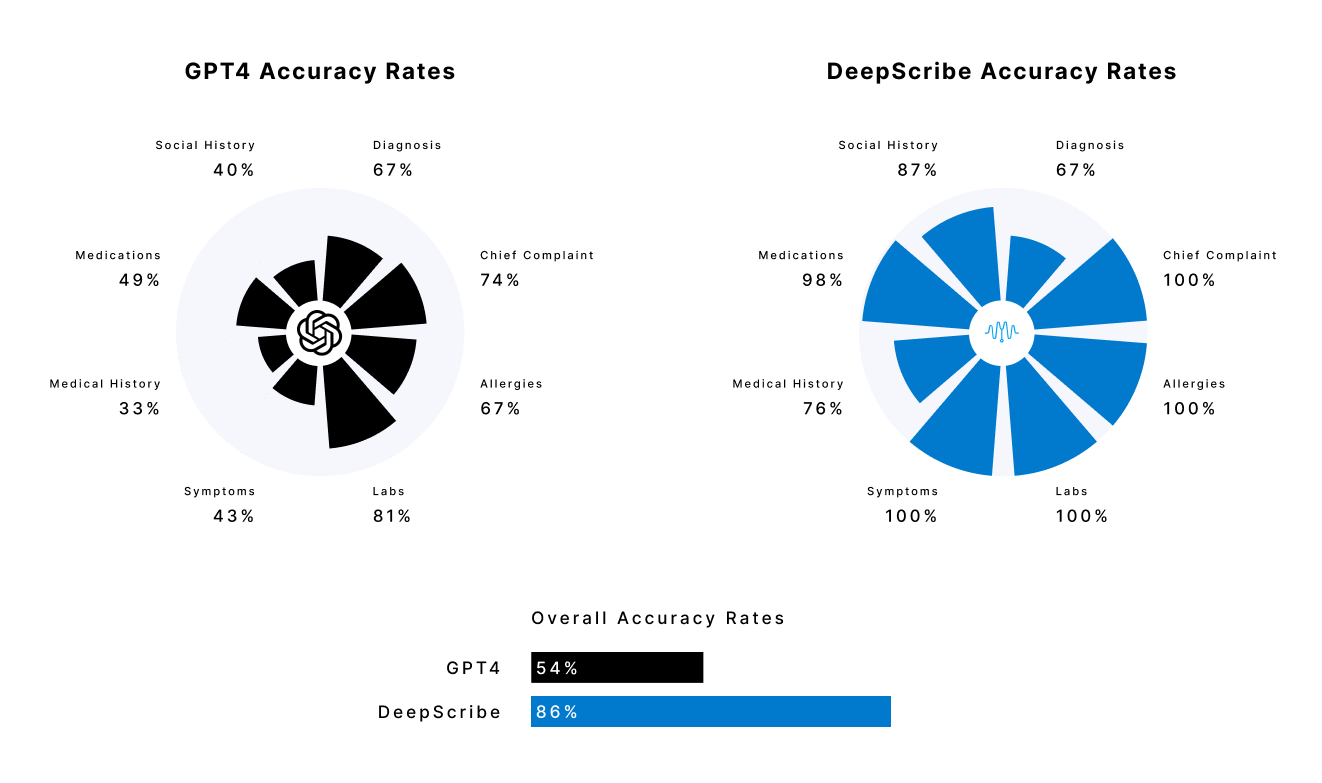
DeepScribe is 59% more accurate than GPT4 when it comes to the clinical accuracy of AI-generated medical notes.
Among critical note categories, here's how the two solutions performed:
Conclusions
There are a few conclusions that we've gathered from the audit of both solutions.
DeepScribe’s Specialized Models are the Difference
DeepScribe's AI performed with significantly higher medical accuracy than GPT4, the reason for which is relatively straight forward:
DeepScribe is trained on millions of real medical encounters that discuss real medical conditions with real medical nuances. GPT4 is not. It is this vast dataset that allows DeepScribe to arrive at more medically accurate conclusions and perform significantly better than AI-powered scribing tools that leverage GPT4.
Without access to the clinical data or specialized models that inform medical conclusions, GPT4 falls way short in automating documentation. GPT4’s medical note outputs have a tendency to “look” good (formatting, style, etc.), but we found the medical accuracy of those outputs to be severely flawed when examined closely.
GPT4's Performance Does Not Discount its Utility
GPT4 is quickly becoming one of the most powerful tools in the world. Its poor performance on clinical accuracy in the AI scribing realm does not discount its utility in other elements of business, ours or others, and its applications in healthcare are not limited to clinical documentation. GPT4 is a tool we envision eventually playing a valuable role in healthcare.
There’s Room to Improve
Compared to clinical standards, DeepScribe performed remarkably well in critical note categories. That being said, after serving thousands of clinicians over the years, we’ve found that the optimal acceptance range for medical notes is around 94% accuracy.
At DeepScribe, we close the remaining accuracy gap through rigorous quality evaluation, continuous model refinement, and strict release criteria. We systematically analyze defects, retrain our AI models on curated data, and only deploy updates that meet predefined safety and performance thresholds. This ensures we are consistently improving accuracy while keeping patient safety and trust at the center of our work.
As the accuracy and interpretability of our AI continue to improve, we’ll keep expanding how transparently we share performance metrics and evaluation methods, furthering our commitment to responsible deployment without ever compromising the core values of trust and safety that DeepScribe is built on.
text
Related Stories


Realize the full potential of Healthcare AI with DeepScribe
Explore how DeepScribe’s customizable ambient AI platform can help you save time, improve patient care, and maximize revenue.

