Medical Voice Recognition Software: How Does It Work?
Learn how medical voice recognition software works, the difference between dictation tools and AI scribes, and why AI-powered solutions offer true documentation relief.


Medical Voice Recognition Software: How Does It Work?
How we communicate in person differs greatly from the manner in which we communicate through written word. Consider a recent conversation of yours that took place in person. Would that conversation have played out the same over email?
Most likely, the answer is no. This is because oral and written communication follow very different etiquette. While you’d likely get to the point rather quickly in a written message, face-to-face conversations are peppered with small talk, digressions, and filler words that are important for building rapport and establishing trust.
Given this mismatch in communication style, it takes significant mental effort to summarize the verbose language of a conversation into concise, readable documentation. We must quickly sort the relevant info from the niceties, all while our memory of the conversation slowly deteriorates. This task is doable if you have just one conversation to keep in mind, but for clinicians who meet with upwards of 20 patients a day, it’s nearly impossible to document every conversation with complete accuracy.
That’s why many clinicians now rely on medical voice recognition software to record and translate patient conversations into medical documentation. If you are considering voice recognition software for your practice, but are finding it difficult to navigate the market – look no further! Below we break down everything you need to know about voice recognition: what it is, how it works, and how to differentiate the market’s options.
What Is Voice Recognition Software?
Voice recognition software is a computer program that can understand human speech and convert it into readable text. Beyond simply understanding human language, voice recognition software can use the information within human speech to complete tasks with greater accuracy.
Everyday applications of voice recognition software include voice-activated assistants like Alexa and Siri, who follow voice commands to complete simple tasks, and automated phone bots who interpret spoken responses in order to direct patrons towards the correct service or support function.
Get the Free eBook: The Complete Guide to Medical Documentation Solutions
Speech Recognition vs. Voice Recognition
Oftentimes, voice recognition and speech recognition in healthcare are used interchangeably. Keeping track of which is which can be difficult, but we find it easier to think of the two like this: speech recognition focuses on interpreting what is spoken, while voice recognition focuses on interpreting what is spoken in addition to who is speaking.
To elaborate:
Speech recognition is used to interpret spoken words and then convert them into digital data or text. Usually, speech recognition software in healthcare takes the form of speech-to-text devices. These devices are often used in a post-session setting where clinician use speech recognition to help dictate their medical notes.
Voice recognition relies on some of the same foundational principles as speech recognition, but builds upon it by also being able to identify the person that the voice belongs to. Outside of the healthcare setting, a common application of voice recognition is performing security authorization through voice. The voice recognition software recognizes, say, a spoken password, but only gives the speaker access if the voice recognition system also recognizes the speaker themselves. A more common example is the setup process a new user goes through when getting acquainted with Alexa or Siri. Those digital assistants learn the nuances of a user's voice and use that comparative data to identify the speaker in the future.
In healthcare, voice recognition can be particularly useful, especially in a patient setting. Voice recognition software that is able to identify a clinician's voice and a patient's voice can more accurately record the spoken interaction between the two during a visit. When we combine voice recognition software with advancing AI and natural language processing, the possibilities immediately become more exciting. More on that later.
How Does Voice Recognition Work?
In general, voice recognition software follows four major steps to translate speech to text:
- First, an analog-to-digital converter translates the analog waves emitted by speech into digital data that can be understood by a computer.
- Then, this data is broken down into smaller sound bites and matched to phonemes in the given language.
- The software analyzes the string of selected phonemes and compares them with its database of known words, phrases, and sentences.
- Following this comparison process, the computer makes an inference about what has been said and either translates that information into text or uses it to perform a command.
Medical voice recognition software follows this same speech-to-text translation process, but requires a database of language specific to the medical field. For that reason, there is a learning curve in which clinicians must correct mistakes made by the software, thereby providing the algorithm feedback to increase accuracy. As accuracy increases, the need for input lessens allowing clinicians to be increasingly hands-off.
What Are The Types Of Medical Voice Recognition Software?
As it applies to medical documentation, there are two main categories of voice recognition software – dictation software and AI scribes.
Dictation tools use a microphone to capture speech and transcribe what it hears word-for-word in real time. Given this process, it is a best practice for clinicians to dictate summaries of their patient visits exactly how they would like them to be recorded in their notes.
AI scribes take this process many steps further. After transcribing audio input word-for-word, AI scribes use natural language processing (NLP) to parse out the medically relevant information while removing small talk and filler words. This allows the clinicians to carry out a natural conversation with their patient as the software listens, transcribes, and summarizes their notes.
Here’s a side-by-side comparison of dictation tools and DeepScribe’s AI scribe. You will notice that while both employ voice recognition to transcribe notes, DeepScribe uses NLP algorithms to generate compliant notes that map to the fields found in an EHR as well the appropriate diagnostic coding needed to meet insurance and billing standards:
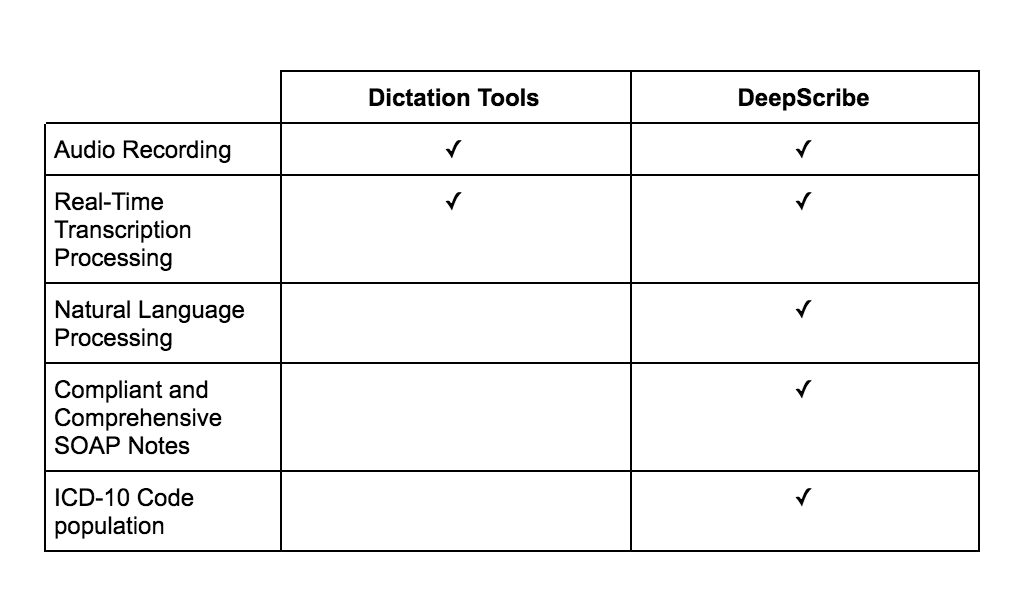
Remember earlier when we discussed the difficulty of summarizing in-person conversations into concise notes, particularly at the scale required of clinicians? Using a dictation tool, clinicians will still need to complete this time-consuming task on their own. Only AI scribes manage note-taking autonomously, providing clinicians complete relief from documentation.
So the final verdict? If you are feeling overwhelmed by administrative demands, and just want to get back to being a clinician, AI-powered voice recognition is the more effective solution.
text
Related Stories


Realize the full potential of Healthcare AI with DeepScribe
Explore how DeepScribe’s customizable ambient AI platform can help you save time, improve patient care, and maximize revenue.

